I told Claude to double-check itself. It got 55% dumber.
Adding a verify step made my AI agent 55% dumber. Here's why asking a weaker tool to check a stronger one always backfires.
Insights and updates from the Supermodel team- Building graph-based world models for coding agents, Benchmarking MCPs, building useful primitives for code factories and more.
Why AI agents burn most of their tokens rediscovering a codebase, and how a small file next to each source file fixes it.


Your AI doesn't see your code as a system. It sees words. Here's what that costs you and what to do about it.

A walk through every public endpoint on the Supermodel API — what each graph represents, why we ship it as a primitive, and what you can build on top.

We benchmarked AI agents on dead code detection across 60+ runs and 14 real-world repositories using Claude Opus 4.6. Graph-enhanced agents achieved 94.1% F1 with 100% precision. The result -- 156x cheaper, 11x faster, 2x better performance than the baseline agent alone. Here's what we learned about context engineering, honest benchmarking, and why code graphs are the missing primitive for software factories.

We benchmarked whether Supermodel can rank the validation files an agent should inspect for a scoped change. On 10 real PRs, scoped ranking found 20 of 21 labeled validation files and beat a path/name baseline by 4.3x F1.

AI agents do not need another dashboard to understand your repo. They need a small graph file next to the code they are already reading.
We ran a test — give Claude Code the same task three ways on a 270k-line Django repo. All had to make 8 failing tests pass. Same model, same starting point. The runs with Supermodel were 40–50% cheaper and 3–4× faster.


You discover tree-sitter, parse a codebase into a graph, render it with a force-directed layout, post a screenshot. It gets hundreds of likes. Then you try it on a real codebase and everything falls apart.

How we redesigned a synchronous monolith into an async control plane and data plane in one calendar week — achieving 10x scale with zero new infrastructure.

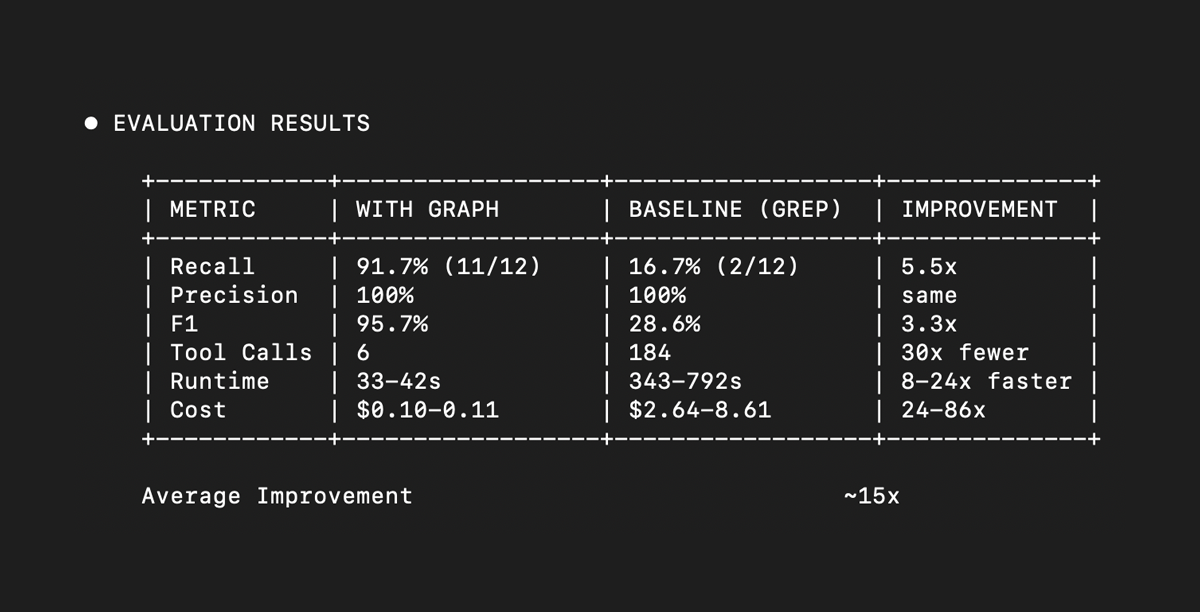
Existing MCP benchmarks rank models, not servers. Here's how to A/B test whether your MCP server actually improves agent performance.

MCP developers ship tools without evidence they work. We built mcpbr to find out. Results from a 500-task controlled SWE-bench experiment.