
When we set out to build Supermodel's Code Graph API, we had one non-negotiable requirement: it had to be fast enough that an AI agent could query it mid-conversation without the user noticing any delay.
That constraint shaped every architectural decision we made.
The Pipeline
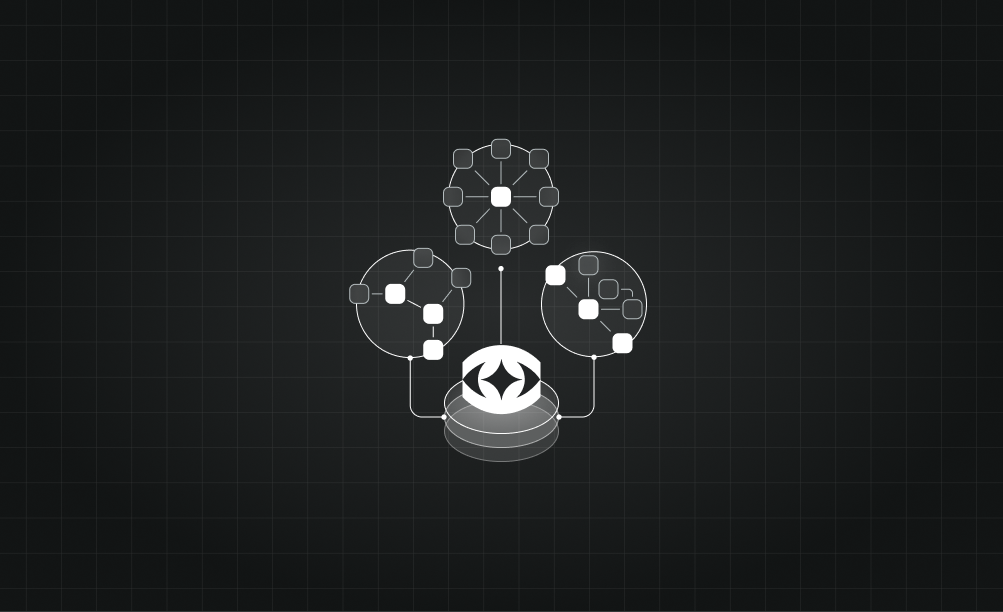
Code comes in, graphs come out. Simple in concept, complex in execution. Here's the pipeline:
- File ingestion — We watch for changes and process only what's new or modified
- Language-specific parsing — AST parsers for each supported language extract structural elements
- Graph construction — Parsed elements become nodes and edges in a directed graph
- Storage and indexing — The graph is stored for fast traversal queries
- API serving — RESTful endpoints expose graph queries with sub-100ms response times
Multi-Language Support
The hardest part wasn't any single language — it was building an abstraction layer that works across all of them. A Python function and a TypeScript function are very different at the syntax level, but structurally similar at the graph level.
We settled on a unified node schema that captures the essential properties of code elements regardless of language: name, kind (function, class, module, etc.), location, and relationships to other nodes.
Performance at Scale
The API processes repositories with millions of lines of code. We can't afford to rebuild the entire graph on every change, so incremental updates were critical from day one.
When a file changes, we invalidate only the nodes that came from that file, re-parse it, and merge the new nodes back into the graph. The merge operation is where the magic happens — it preserves cross-file relationships while updating the changed portions.
What's Next
We're working on semantic analysis that goes beyond structural relationships. Understanding not just that function A calls function B, but why — what data flows between them, what invariants they share, what patterns they form together.
The code graph is the foundation. Everything we build next sits on top of it.