
We built Uncompact because we got tired of watching our AI agents forget everything.
Every day, we'd start a coding session with Claude Code, get deep into a refactor, and then — compaction. The agent would lose track of where we were, what files mattered, and how the pieces fit together. We'd spend the next 10 minutes re-explaining context that the agent had perfectly understood 30 seconds earlier.
The Real Problem
The issue isn't compaction itself. Compaction is necessary — context windows are finite. The problem is that agents don't have anywhere to store structural understanding outside the conversation.
Think about how you work as a developer. You don't keep every detail of your codebase in working memory. You have mental models, you know where to look things up, and you have tools (IDEs, grep, documentation) that let you recover context quickly.
AI agents had none of that. Until now.
What We Built
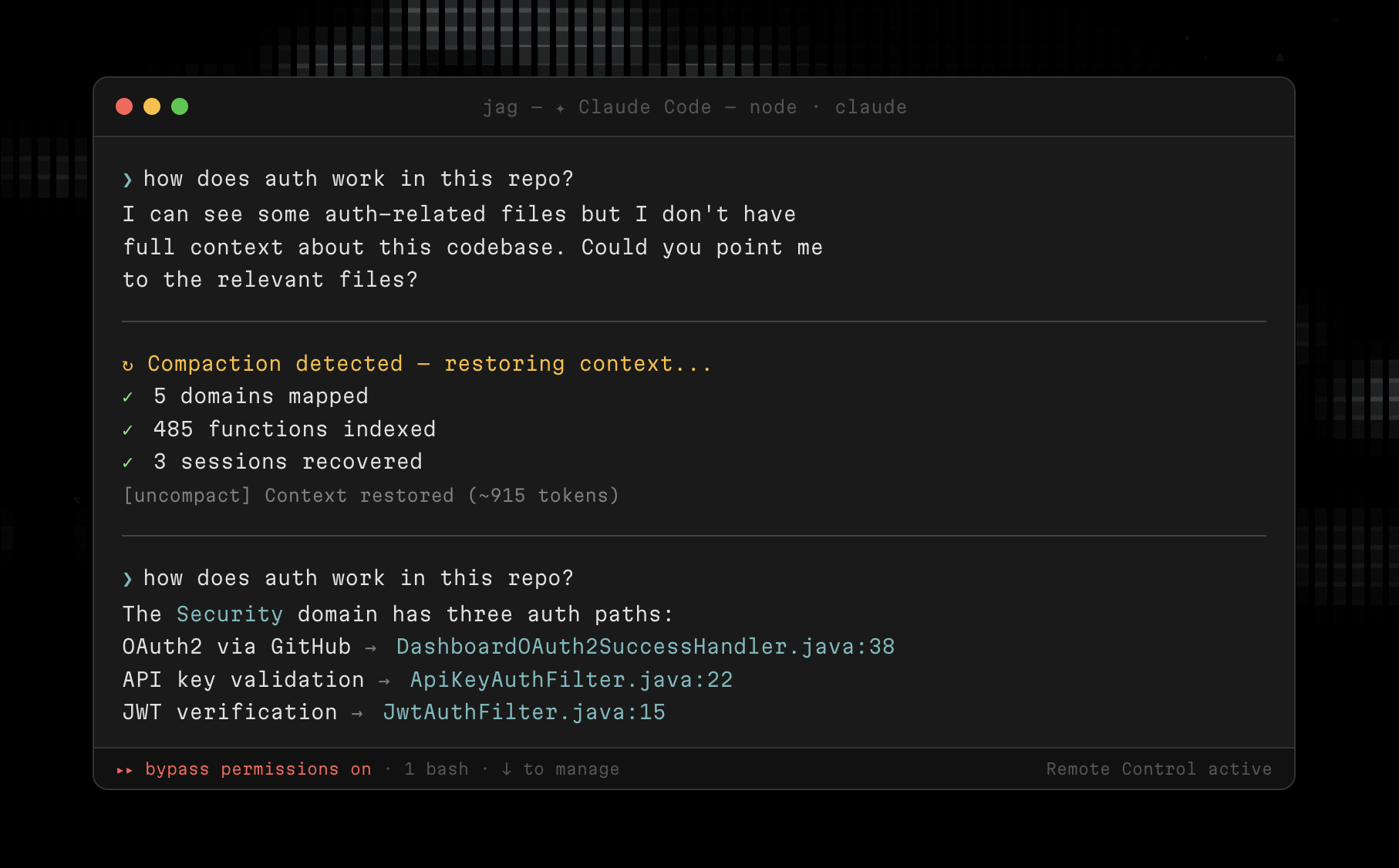
Uncompact maintains a persistent code graph that survives compaction. When an agent needs to understand your codebase structure, it queries the graph instead of re-reading files.
The key insight was that the graph needs to be always current. A stale graph is worse than no graph, because it gives the agent false confidence. So we built Uncompact to update incrementally — every file save triggers a partial graph update, not a full rebuild.
Getting Started
Installing Uncompact takes about two minutes. Run npm install -g uncompact --foreground-scripts (the --foreground-scripts flag is required so the auth prompt appears in your terminal), then run uncompact auth login to connect your Supermodel API key. Uncompact registers itself as a Claude Code hook automatically during setup.
From that point, every file save triggers a partial graph update against the Supermodel API, and the graph is available to Claude Code immediately. No additional configuration required on the agent side.
How Incremental Updates Work
The key engineering decision was how to keep the graph current without making every file save expensive.
A naive approach rebuilds the entire graph on every change. That works for small projects but breaks down quickly at scale. For a project with 50,000 lines of code, a full rebuild on every file save is not practical.
Instead, Uncompact tracks which files have changed and re-processes only those files and their immediate neighbors in the graph. If you edit PaymentService.ts, Uncompact re-analyzes that file and updates the edges connecting it to its callers and callees. The rest of the graph is untouched. Updates are fast regardless of total codebase size.
This is the same principle behind incremental compilation: do the minimum work necessary to bring the model back to a consistent state, not a full rebuild from scratch.
What the Agent Actually Experiences
Here is what changes from the agent's perspective.
Without Uncompact, after a compaction event, the agent retains whatever survived the context trim. If it was deep into a refactor, it might still have the most recent file it was editing, but it loses the broader picture: which other files call into the one it is working on, what the dependency chain looks like, what decisions were made before the context limit hit.
With Uncompact, the agent queries the graph instead. "What calls processPayment?" is a graph query, not a context search. The answer is always accurate, always current, and always available regardless of how many times the context has compacted. The agent picks up exactly where it left off, with the same structural understanding it had before compaction.
Lessons Learned
Start simple. Our first version tried to capture everything — every variable, every type, every import. It was too noisy. The version that actually works focuses on the relationships that matter most: function calls, module dependencies, and type hierarchies.
Make it invisible. If developers have to think about the code graph, they won't use it. Uncompact runs as a background process that the agent queries automatically. No setup, no configuration, no maintenance.
Trust the graph, verify the details. The graph tells the agent where to look. The agent still reads the actual code when it needs specifics. This layered approach keeps things fast without sacrificing accuracy.