
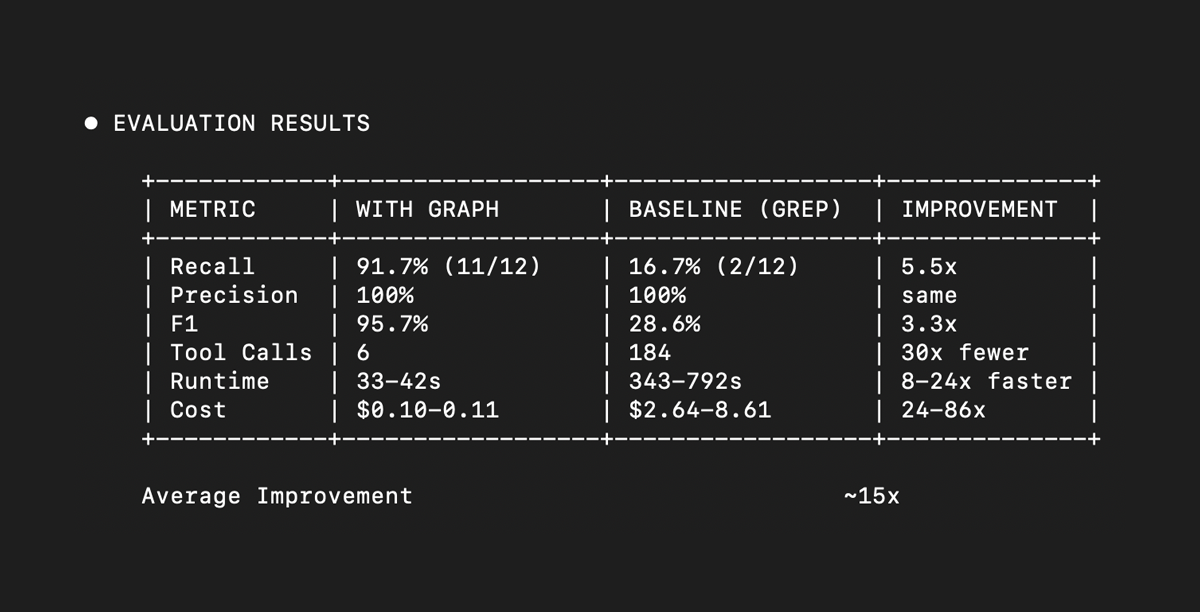
Over 8,000 Model Context Protocol servers were registered in 2025. Very few have published evidence of making agents more useful at real tasks.
The benchmarks that exist measure the wrong thing. They test whether models can use MCP tools correctly. They don't test whether adding an MCP server actually improves outcomes.
What existing benchmarks measure
- MCP-Bench: How well LLMs discover, select, and use tools from 28 open source servers
- MCP-Atlas: How well LLMs orchestrate complex multi-tool workflows
- MCP-Universe: How LLMs perform on hard tasks with unseen tools
What they don't measure
None answer the question MCP developers actually need answered: "Does adding MY server to MY agent improve task completion?" A developer needs the marginal effect of one server on one agent across diverse real-world cases.
It is entirely possible to build an MCP server with 100% adoption, 0% failure rate, that still reduces general task performance. We know this because we've measured it across tens of runs on 500 SWE-bench Verified tasks.
A/B testing for MCP servers
The answer is paired comparison. Same agent, same tasks, twice: once with your MCP server, once without. Hundreds of task datasets exist for this (SWE-bench, TerminalBench, more). The infrastructure for controlled experiments was there. What was missing was a tool to run them.
We built mcpbr to automate exactly this. Paired experiments across any task dataset, resolution deltas, statistical significance. Open source. Full methodology in the companion post.
What we found
We tested an experimental MCP server with Claude Sonnet 4 across 500 SWE-bench Verified tasks. Resolution rate dropped from 49.8% to 42.4%, even as cost fell ~15%. The effect varied wildly by repository — neutral on some, devastating on others. None of this was visible without a controlled experiment.
| Metric | Baseline | With MCP | Change |
|---|---|---|---|
| Tasks resolved | 249/500 (49.8%) | 212/500 (42.4%) | -14.9% relative |
| Only MCP passes | — | 18 | |
| Only baseline passes | 55 | — |
The traces from that run let us redesign the tool interface and test each iteration against the last. Ship on data, not vibes.
Test your MCP server
If you're shipping an MCP server, benchmark it before your users do. Point it at a task dataset and get real numbers on what your server does to agent performance. One controlled run tells you more than any leaderboard.
Published by the Supermodel Tools team. mcpbr has since evolved into matchspec, the evaluation layer of the MIST stack.